Inside React Query


- Earlier parts of the series are hidden
- #17: Seeding the Query Cache
- #18: Inside React QueryCurrent
- #19: Type-safe React Query
- Later parts of the series are hidden
All 33 parts in the series
- #1: Practical React Query
- #2: React Query Data Transformations
- #3: React Query Render Optimizations
- #4: Status Checks in React Query
- #5: Testing React Query
- #6: React Query and TypeScript
- #7: Using WebSockets with React Query
- #8: Effective React Query Keys
- #8a: Leveraging the Query Function Context
- #9: Placeholder and Initial Data in React Query
- #10: React Query as a State Manager
- #11: React Query Error Handling
- #12: Mastering Mutations in React Query
- #13: Offline React Query
- #14: React Query and Forms
- #15: React Query FAQs
- #16: React Query meets React Router
- #17: Seeding the Query Cache
- #18: Inside React QueryCurrent
- #19: Type-safe React Query
- #20: You Might Not Need React Query
- #21: Thinking in React Query
- #22: React Query and React Context
- #23: Why You Want React Query
- #24: The Query Options API
- #25: Automatic Query Invalidation after Mutations
- #26: How Infinite Queries work
- #27: React Query API Design - Lessons Learned
- #28: React Query - The Bad Parts
- #29: Concurrent Optimistic Updates in React Query
- #30: React Query Selectors, Supercharged
- #31: Creating Query Abstractions
- #32: TanStack Router and Query
I’ve been asked a lot lately how React Query works internally. How does it know when to re-render? How does it de-duplicate things? How come it’s framework-agnostic?
These are all very good questions - so let’s take a look under the hood of our beloved async state management library and analyze what really happens when you call useQuery.
To understand the architecture, we have to start at the beginning:
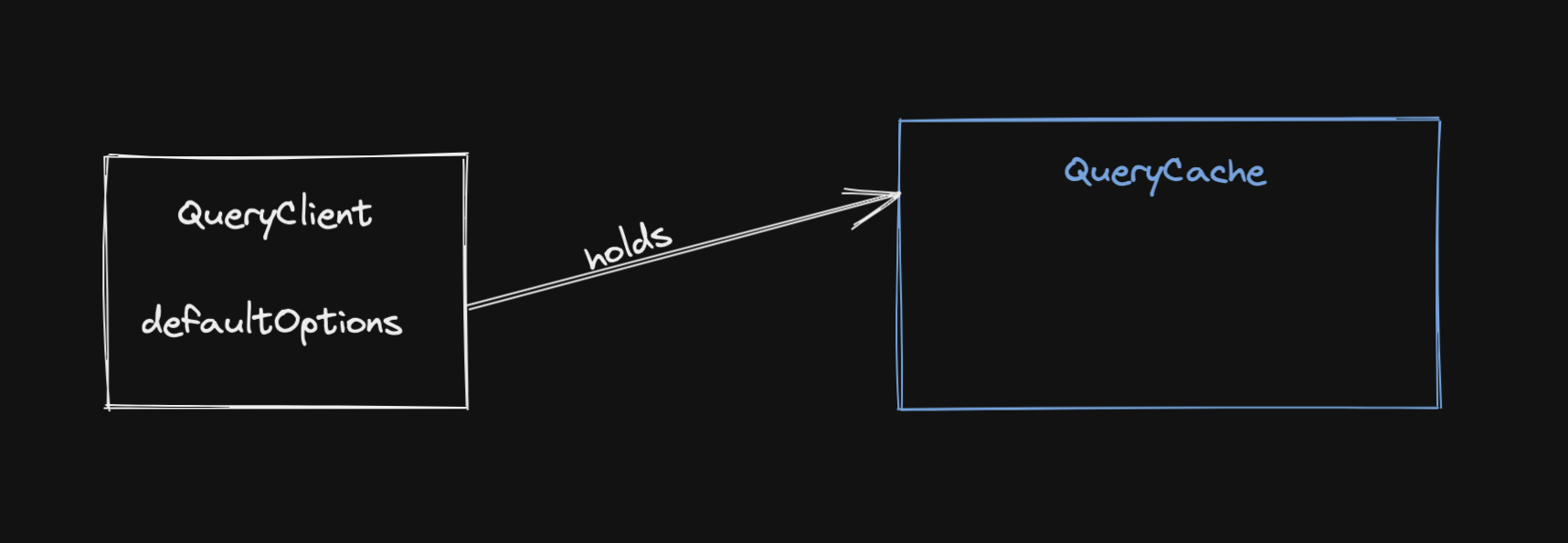
It all starts with a QueryClient. That’s the class you create an instance of, likely at the start of your application, and then make available everywhere via the QueryClientProvider:
import { QueryClient, QueryClientProvider,} from '@tanstack/react-query'
// ⬇️ this creates the clientconst queryClient = new QueryClient()
function App() { return ( // ⬇️ this distributes the client <QueryClientProvider client={queryClient}> <RestOfYourApp /> </QueryClientProvider> )}The QueryClientProvider uses React Context (opens in a new window) to distribute the QueryClient throughout the entire application. The client itself is a stable value - it’s created once (make sure you don’t inadvertently re-create it too often), so this is a perfect case for using Context. It will not make your app re-render - it just gives you access to this client via useQueryClient.
It might not be well known, but the QueryClient itself doesn’t really do much. It’s a container for the QueryCache and the MutationCache, which are automatically created when you create a new QueryClient.
It also holds some defaults that you can set for all your queries and mutations, and it provides convenience methods to work with the caches. In most situations, you will not interact with the cache directly - you will access it through the QueryClient.
Alright, so the client lets us work with the cache - what is the cache?
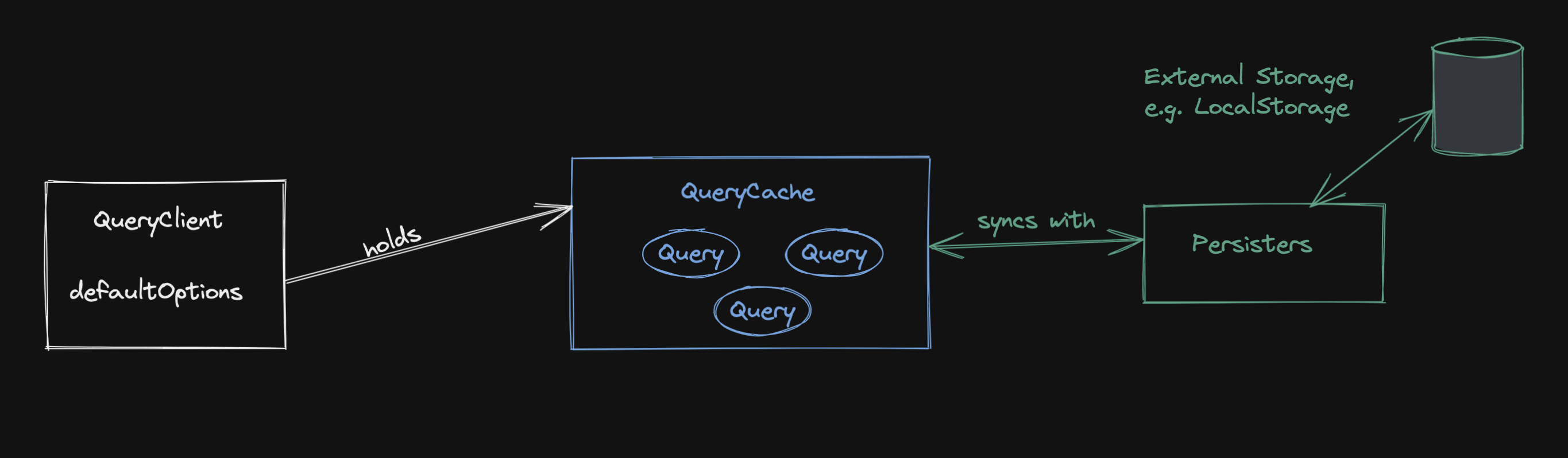
Simply put - the QueryCache is an in-memory object where the keys are a stably serialized version of your queryKeys (called a queryKeyHash) and the values are an instance of the Query class.
I think it’s important to understand that React Query, per default, only stores data in-memory and nowhere else. If you reload your browser page, the cache is gone. Have a look at the persisters (opens in a new window) if you want to write the cache to an external storage like localstorage.
The cache has queries, and a Query is where most of the logic is happening. It not only contains all the information about a query (its data, status field or meta information like when the last fetch happened), it also executes the query function and contains the retry, cancellation and de-duplication logic.
It has an internal state machine to make sure we don’t wind up in impossible states. For example, if a query function should be triggered while we are already fetching, that fetch can be de-duplicated. If a query is cancelled, it goes back to its previous state.
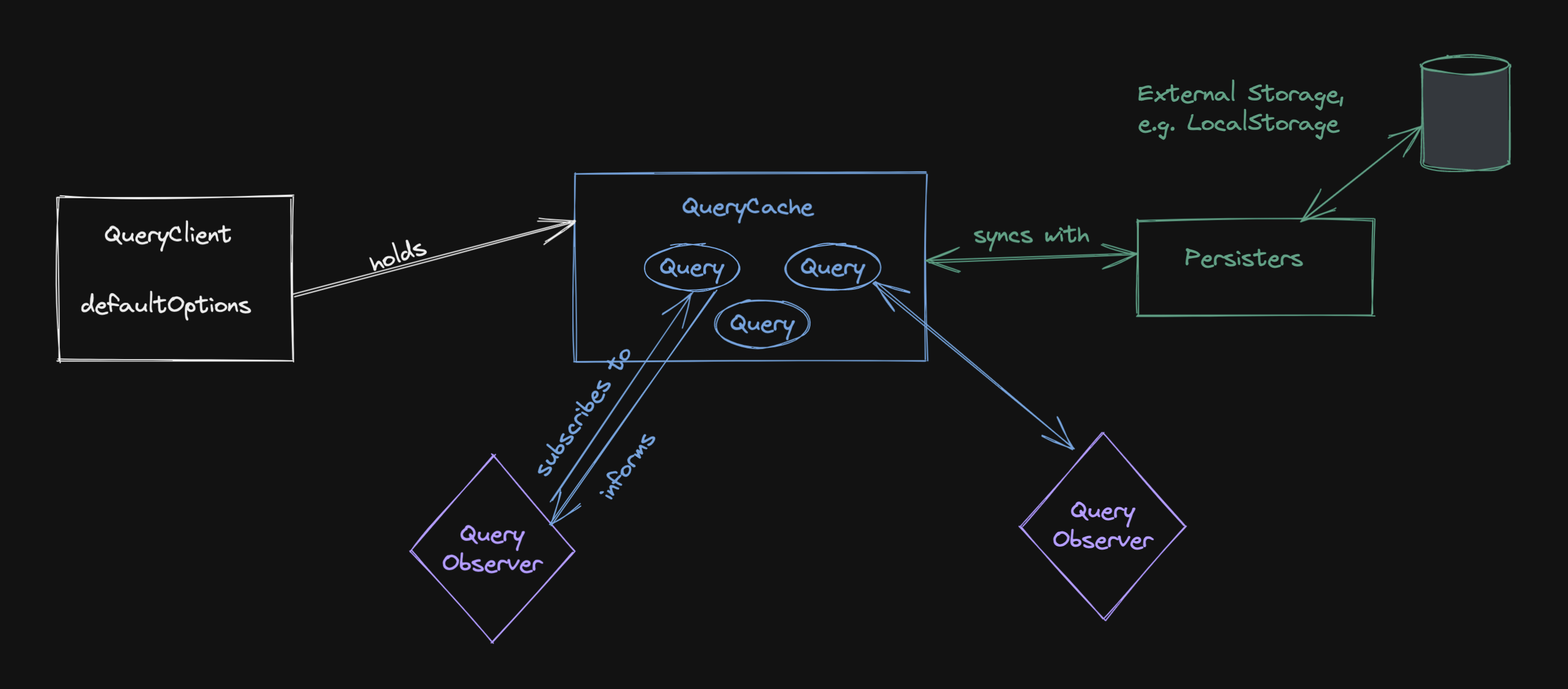
Most importantly, the query knows who’s interested in the query data, and it can inform those Observers about all changes.
Observers are the glue between the Query and the components that want to use it. An Observer is created when you call useQuery, and it is always subscribed to exactly one query. That’s why you have to pass a queryKey to useQuery. 😉
The Observer does a bit more though - it’s where most of the optimizations happen. The Observer knows which properties of the Query a component is using, so it doesn’t have to notify it of unrelated changes. As an example, if you only use the data field, the component doesn’t have to re-render if isFetching is changing on a background refetch.
Even more - each Observer can have a select option, where you can decide which parts of the data field you are interested in. I’ve written about this optimization before in #2: React Query Data Transformations. Most of the timers, like ones for staleTime or interval fetching, also happen on the observer-level.
A Query without an Observer is called an inactive query. It’s still in the cache, but it’s not being used by any component. If you take a look at the React Query Devtools, you will see that inactive queries are greyed out. The number on the left side indicates the number of Observers that are subscribed to the query.
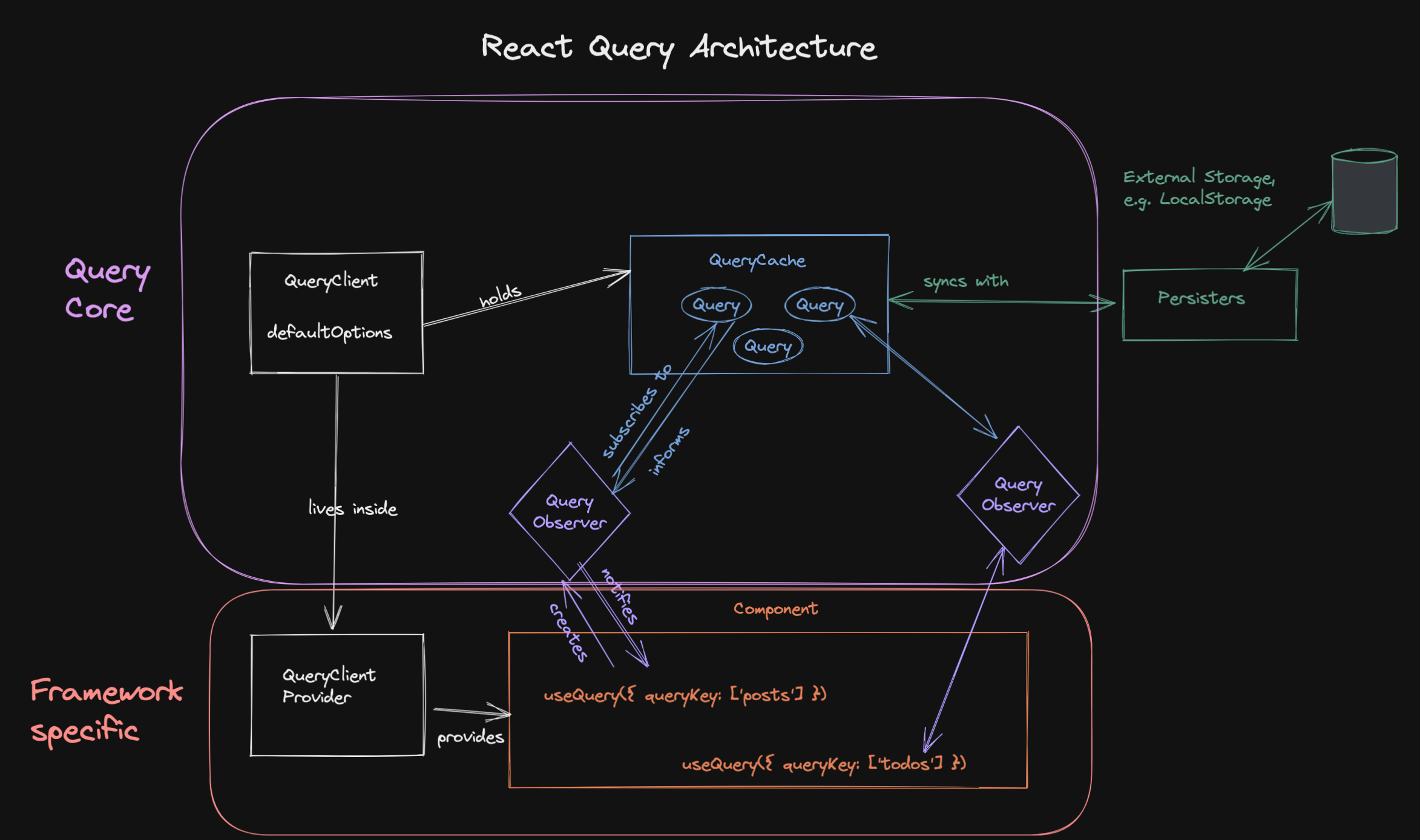
Putting it all together, we can see that most of the logic lives inside the framework-agnostic Query Core: QueryClient, QueryCache, Query and QueryObserver are all there.
That’s why it’s fairly straightforward to create an adapter for a new framework. You basically need a way to create an Observer, subscribe to it, and re-render your component if the Observer is notified. The useQuery adapters for react (opens in a new window) and solid (opens in a new window) each have around 100 lines of code only.
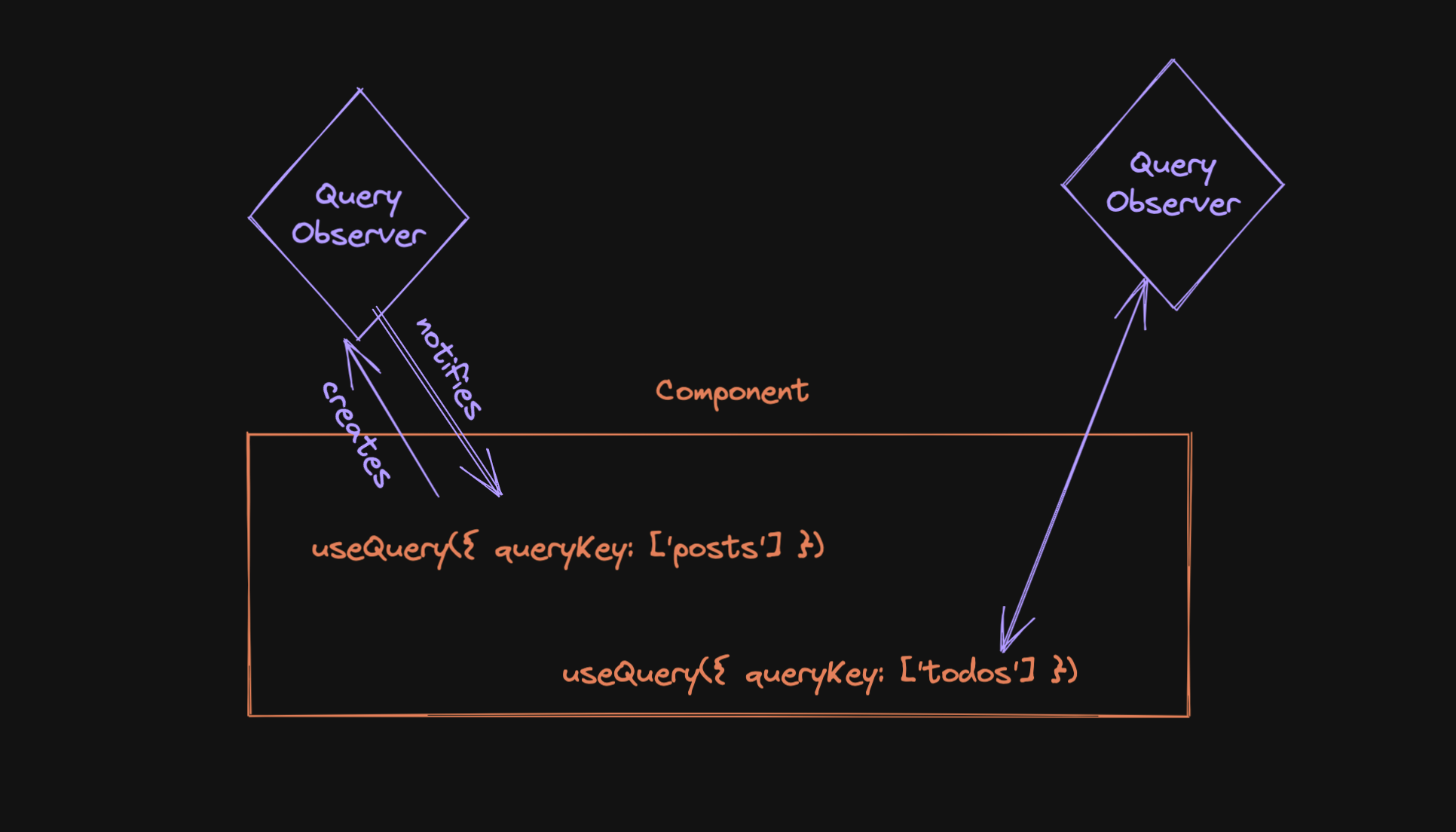
Lastly, let’s look at the flow from another angle - starting with a component:
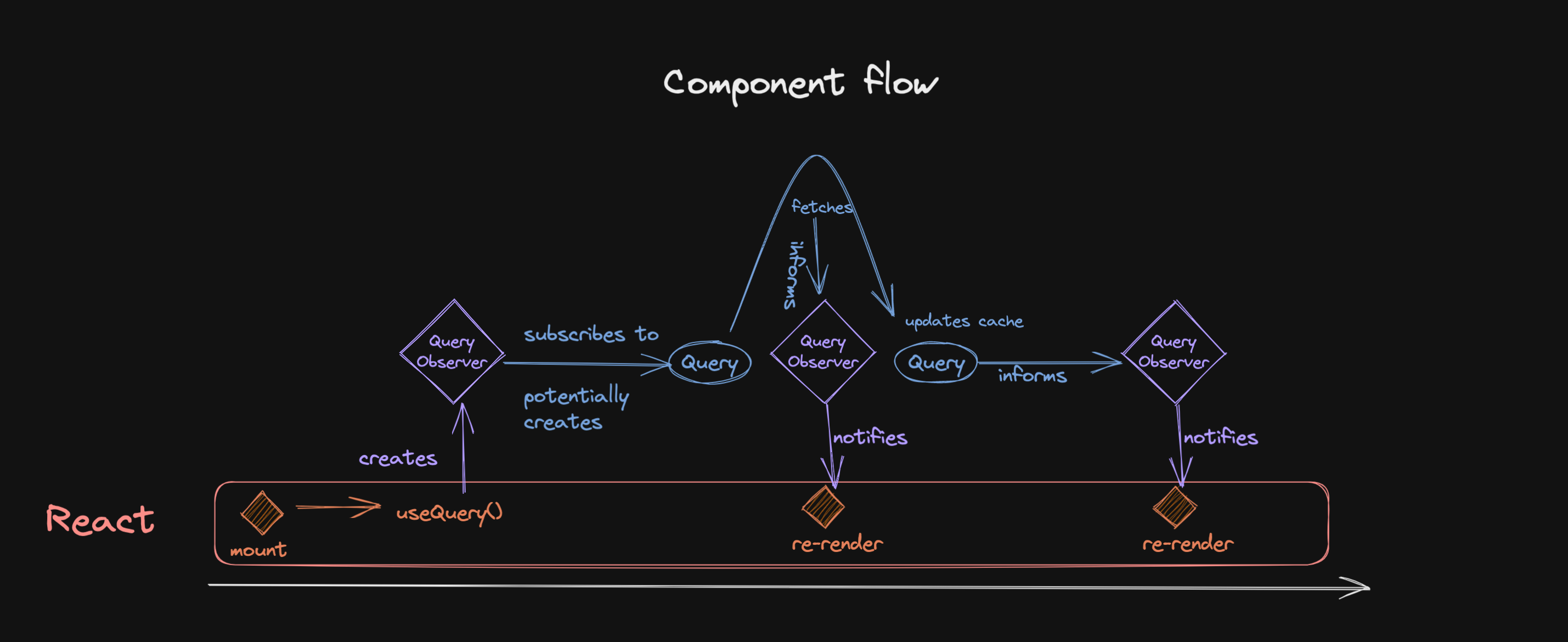
- the component mounts, it calls
useQuery, which creates anObserver. - that
Observersubscribes to theQuery, which lives in theQueryCache. - that subscription might trigger the creation of the
Query(if it doesn’t yet exist), or it might trigger a background refetch if data is deemed stale. - starting a fetch changes the state of the
Query, so theObserverwill be informed about that. - The
Observerwill then run some optimizations and potentially notify the component about the update, which can then render the new state. - after the
Queryhas finished running, it will inform theObserverabout that as well.
Please note that this is just one of many potential flows. Ideally, data would be in the cache already when the component mounts - you can read more about that in #17: Seeding the Query Cache.
What’s the same for all flows is that most of the logic happens outside of React (or Solid or Vue), and that every update from the state machine is propagated to the Observer, who then decides if the component should also be informed.
I hope it’s now a bit clearer how React Query works internally. As always, feel free to reach out to me on bluesky (opens in a new window) if you have any questions, or just leave a comment below. ⬇️





