Seeding the Query Cache


Last Update: 2023-10-21
- Earlier parts of the series are hidden
- #16: React Query meets React Router
- #17: Seeding the Query CacheCurrent
- #18: Inside React Query
- Later parts of the series are hidden
All 33 parts in the series
- #1: Practical React Query
- #2: React Query Data Transformations
- #3: React Query Render Optimizations
- #4: Status Checks in React Query
- #5: Testing React Query
- #6: React Query and TypeScript
- #7: Using WebSockets with React Query
- #8: Effective React Query Keys
- #8a: Leveraging the Query Function Context
- #9: Placeholder and Initial Data in React Query
- #10: React Query as a State Manager
- #11: React Query Error Handling
- #12: Mastering Mutations in React Query
- #13: Offline React Query
- #14: React Query and Forms
- #15: React Query FAQs
- #16: React Query meets React Router
- #17: Seeding the Query CacheCurrent
- #18: Inside React Query
- #19: Type-safe React Query
- #20: You Might Not Need React Query
- #21: Thinking in React Query
- #22: React Query and React Context
- #23: Why You Want React Query
- #24: The Query Options API
- #25: Automatic Query Invalidation after Mutations
- #26: How Infinite Queries work
- #27: React Query API Design - Lessons Learned
- #28: React Query - The Bad Parts
- #29: Concurrent Optimistic Updates in React Query
- #30: React Query Selectors, Supercharged
- #31: Creating Query Abstractions
- #32: TanStack Router and Query
A new RFC about first class support for Promises (opens in a new window) has been released last week, and it got some talk going about how this would introduce fetch waterfalls if used incorrectly. So what are fetch waterfalls exactly?
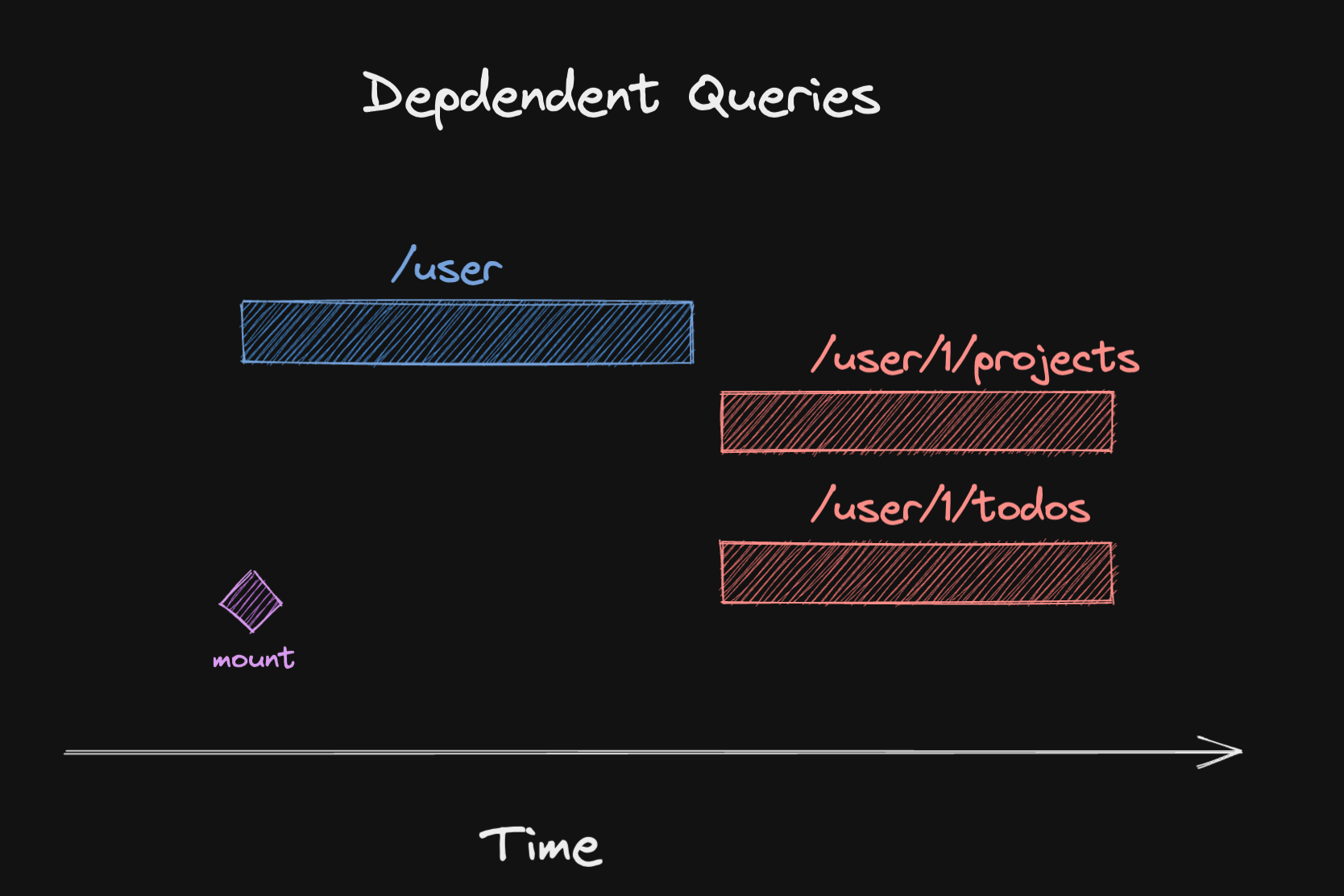
A waterfall describes a situation where one request is made, and we wait for it to complete before firing another request.
Sometimes, this is unavoidable, because the first request contains information that is needed to make the second request. We also refer to these as dependent queries (opens in a new window):
In many cases though, we can actually fetch all the data we need in parallel, because it is independent data:
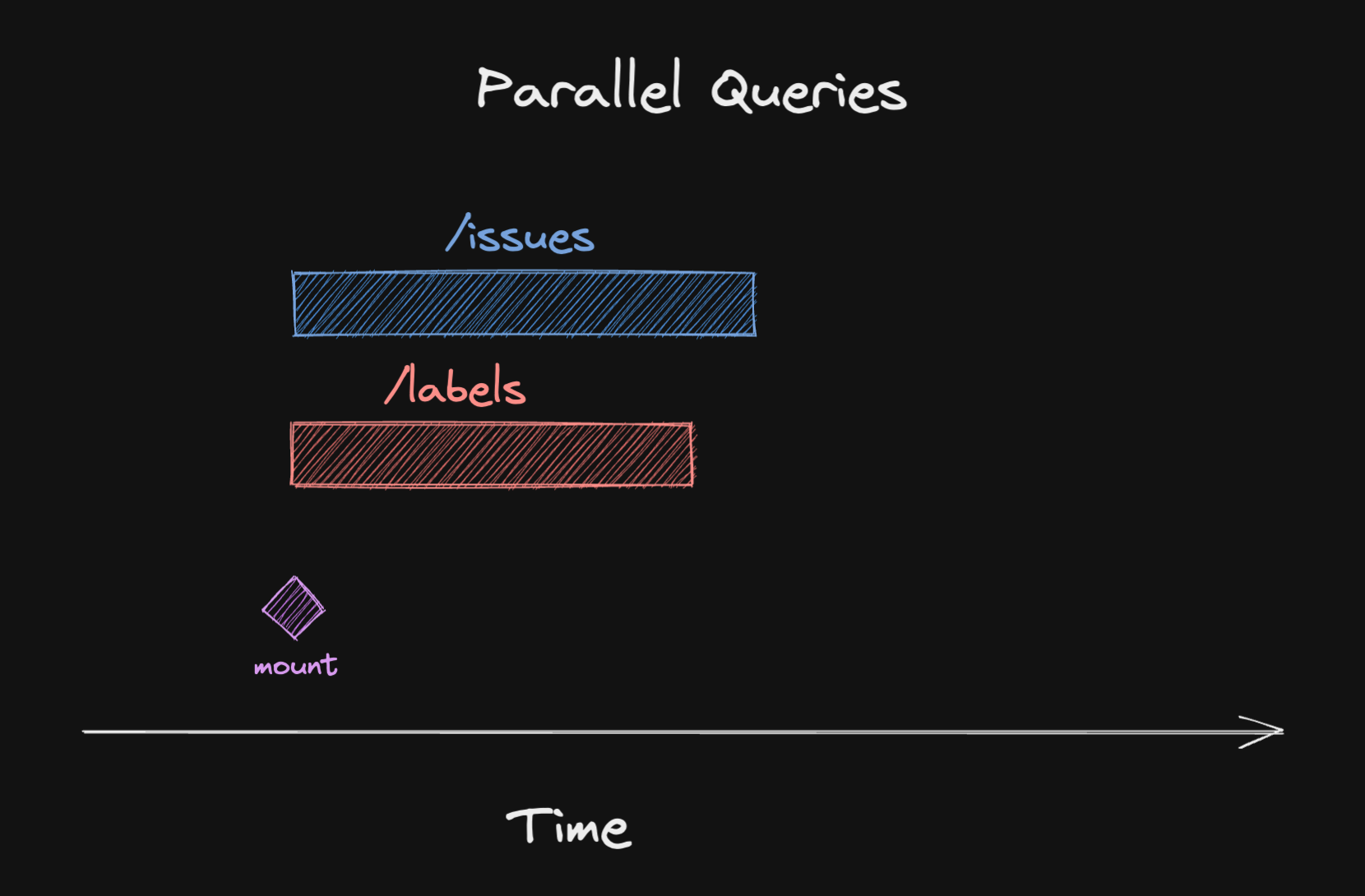
In React Query, we can do that in two different ways:
// 1. Use useQuery twiceconst issues = useQuery({ queryKey: ['issues'], queryFn: fetchIssues,})const labels = useQuery({ queryKey: ['labels'], queryFn: fetchLabels,})
// 2. Use the useQueries hookconst [issues, labels] = useQueries([ { queryKey: ['issues'], queryFn: fetchIssues }, { queryKey: ['labels'], queryFn: fetchLabels },])In both variants, React Query will kick off data fetching in parallel. So where do waterfalls come in?
As described in the above linked RFC, suspense is a way to unwrap promises with React. A defining trait of promises is that they can be in three different states: pending, fulfilled or rejected.
When rendering components, we are mostly interested in the success scenario. Handling loading and error states in each and every component can be tedious, and suspense is aimed at solving this problem.
When a promise is pending, React will unmount the component tree and render a fallback defined by a Suspense boundary component. In case of errors, the error is bubbled up to the nearest ErrorBoundary.
This will decouple our components from handling those states, and we can focus on the happy path. It almost acts like synchronous code that just reads a value from a cache. React Query offers a dedicated useSuspenseQuery hook for that since v5:
function Issues() { // 👓 read data from cache const { data } = useSuspenseQuery({ queryKey: ['issues'], queryFn: fetchIssues, })
// 🎉 no need to handle loading or error states
return ( <div> {/* TypeScript knows data can't be undefined */} {data.map((issue) => ( <div>{issue.title}</div> ))} </div> )}
function App() { // 🚀 Boundaries handle loading and error states return ( <Suspense fallback={<div>Loading...</div>}> <ErrorBoundary fallback={<div>On no!</div>}> <Issues /> </ErrorBoundary> </Suspense> )}So this is nice and all, but it can backfire when you use multiple queries in the same component that have suspense turned on. Here is what happens:
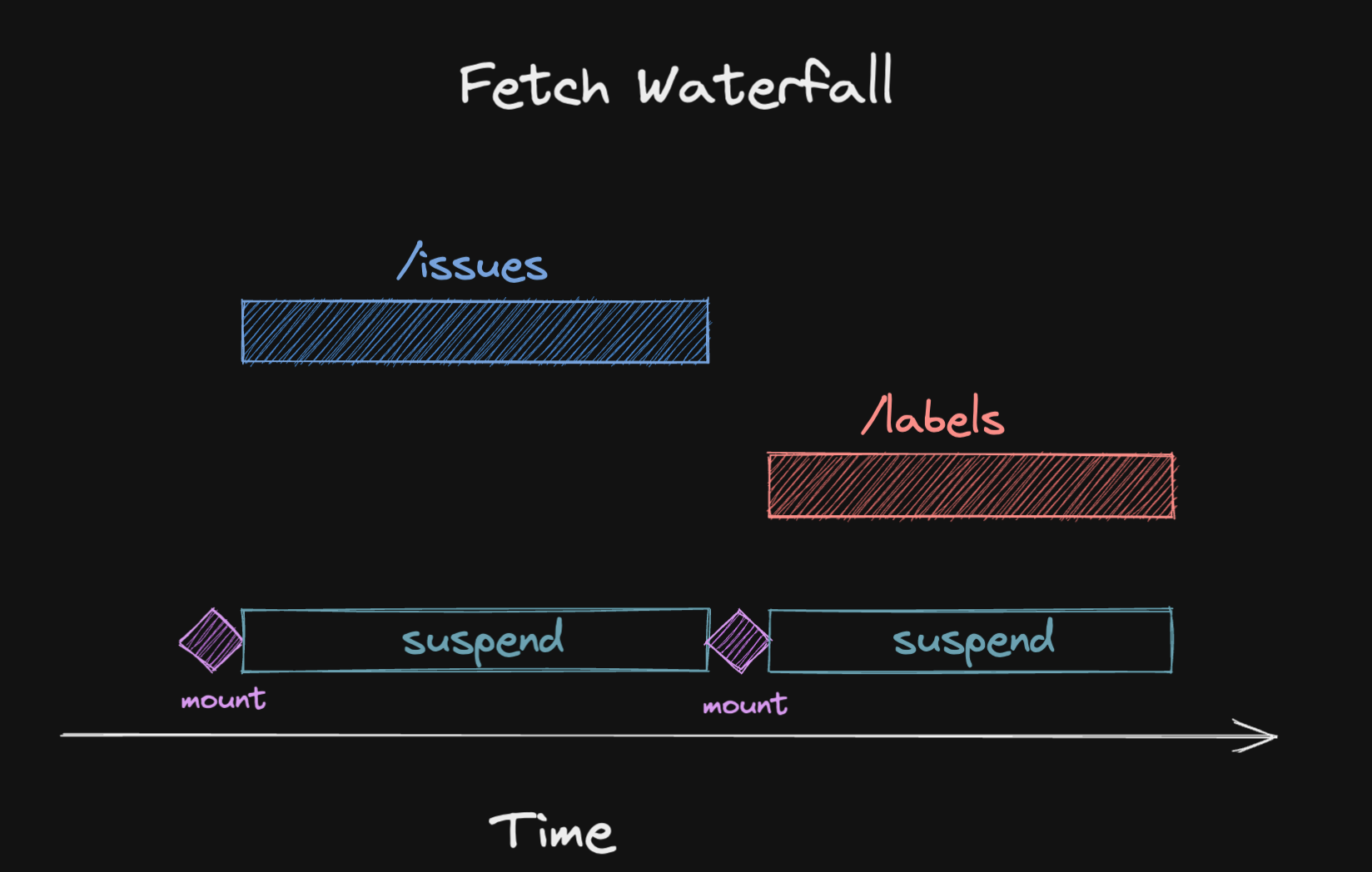
- Component renders, tries to read the first query
- Sees that there is no data in the cache yet, so it suspends
- This unmounts the component tree, and renders the fallback
- When the fetch is finished, the component tree is remounted
- First query is now read successfully from the cache
- Component sees the second query, and tries to read it
- Second query has no data in the cache, so it suspends (again)
- Second query is fetched
- Component finally renders successfully
This will have pretty impactful implications on your application’s performance, because you’ll see that fallback for waaay longer than necessary.
The best way to circumvent this problem is to stick to one query per component, or to make sure that there is already data in the cache when the component tries to read it.
The earlier you initiate a fetch, the better, because the sooner it starts, the sooner it can finish. 🤓
- If your architecture supports server side rendering - consider fetching on the server (opens in a new window).
- If you have a router that supports loaders, consider prefetching there (opens in a new window).
But even if that’s not the case, you can still use prefetchQuery to initiate a fetch before the component is rendered:
const issuesQuery = { queryKey: ['issues'], queryFn: fetchIssues }
// ⬇️ initiate a fetch before the component rendersqueryClient.prefetchQuery(issuesQuery)
function Issues() { const issues = useSuspenseQuery(issuesQuery)}The call to prefetchQuery is executed as soon as your JavaScript bundle is evaluated. This works very well if you do route base code splitting (opens in a new window), because it means the code for a certain page will be lazily loaded and evaluated as soon as the user navigates to that page.
This means it will still be kicked off before the component renders. If you do this for both queries in our example, you will get those parallel queries back even when using suspense.
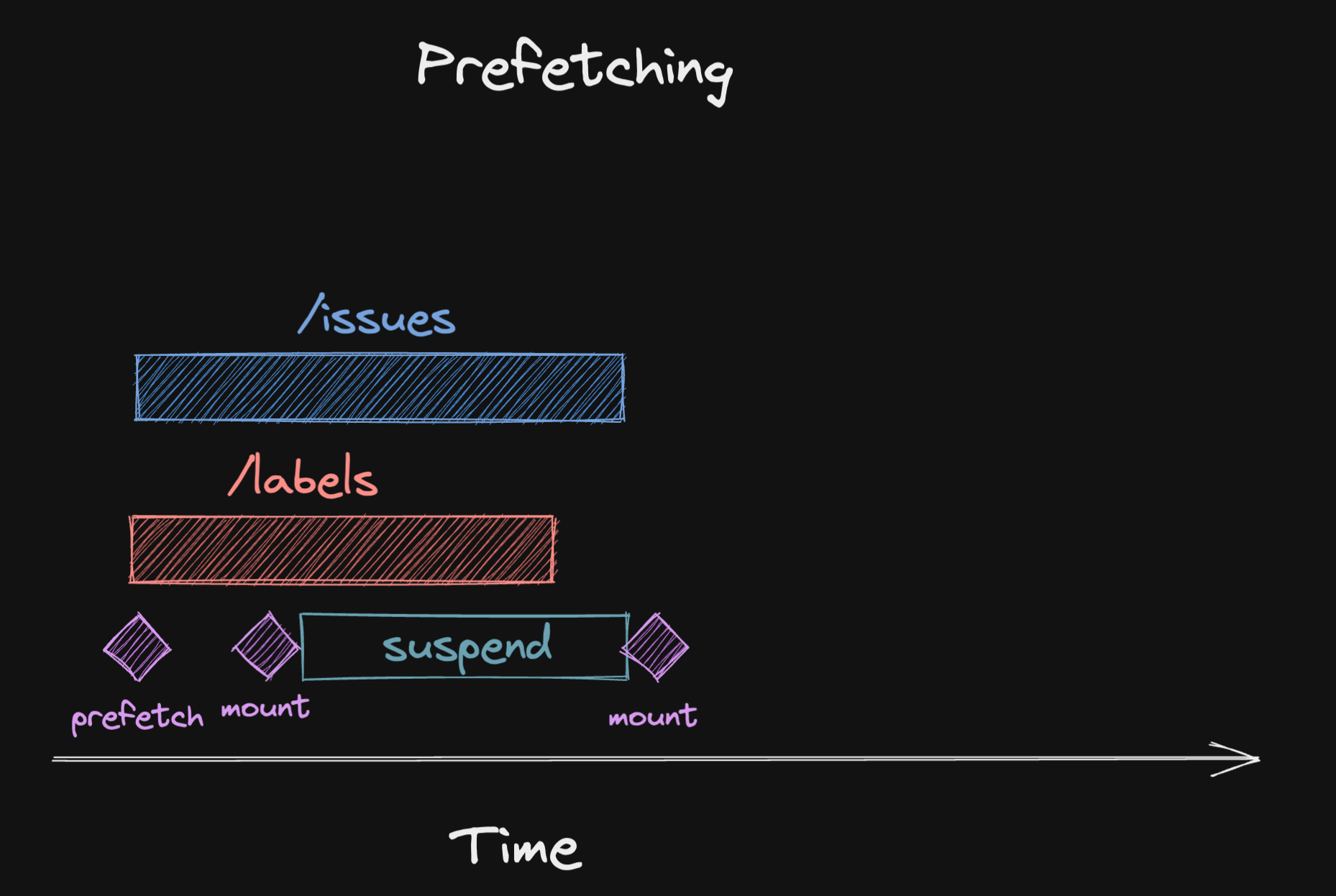
As we can see, the query will still suspend until both are done fetching, but because we’ve triggered them in parallel, the waiting time is now drastically reduced.
Note: useQueries doesn’t support suspense right now, but it might do in the future. If we add support, the goal is to trigger all fetches in parallel to avoid those waterfalls.
I don’t know enough about the RFC yet to properly comment on it. A big part is still missing, namely how the cache API will work. I do think it is a bit problematic that the default behaviour will lead to waterfalls unless developers explicitly seed the cache early on. I’m still pretty excited about it because it will likely make internals of React Query easier to understand and maintain. It remains to be seen if it is something that will be used in userland a lot.
Another nice way to make sure that your cache is filled by the time it is read is to seed it from other parts of the cache. Oftentimes, if you render a detail view of an item, you will have data for that item readily available if you’ve previously been on a list view that shows a list of items.
There are two common approaches to fill a detail cache with data from a list cache:
This is the one also described in the docs (opens in a new window): When you try to render the detail view, you look up the list cache for the item you want to render. If it is there, you use it as initial data for the detail query.
const useTodo = (id: number) => { const queryClient = useQueryClient() return useQuery({ queryKey: ['todos', 'detail', id], queryFn: () => fetchTodo(id), initialData: () => { // ⬇️ look up the list cache for the item return queryClient .getQueryData(['todos', 'list']) ?.find((todo) => todo.id === id) }, })}If the initialData function returns undefined, the query will proceed as normal and fetch the data from the server. And if something is found, it will be put into the cache directly.
Be advised that if you have staleTime set, no further background refetch will occur, as initialData is seen as fresh. This might not be what you want if your list was last fetched twenty minutes ago.
As shown in the docs (opens in a new window), we can additionally specify initialDataUpdatedAt on our detail query. It will tell React Query when the data we are passing in as initialData was originally fetched, so it can determine staleness correctly. Conveniently, React Query also knows when the list was last fetched, so we can just pass that in:
const useTodo = (id: number) => { const queryClient = useQueryClient() return useQuery({ queryKey: ['todos', 'detail', id], queryFn: () => fetchTodo(id), initialData: () => { return queryClient .getQueryData(['todos', 'list']) ?.find((todo) => todo.id === id) }, initialDataUpdatedAt: () => // ⬇️ get the last fetch time of the list queryClient.getQueryState(['todos', 'list'])?.dataUpdatedAt, })}🟢 seeds the cache “just in time”
🔴 needs more work to account for staleness
Alternatively, you can create detail caches whenever you fetch the list query. This has the advantage that staleness is automatically measured from when the list was fetched, because, well, that’s when we create the detail entry.
However, there is no good callback to hook into when a query is fetched. The global onSuccess callback on the cache itself might work, but it would be executed for every query, so we’d have to narrow it down to the right query key.
The best way I’ve found to execute the push approach is to do it directly in the queryFn, after data has been fetched:
const useTodos = () => { const queryClient = useQueryClient() return useQuery({ queryKey: ['todos', 'list'], queryFn: async () => { const todos = await fetchTodos() todos.forEach((todo) => { // ⬇️ create a detail cache for each item queryClient.setQueryData(['todos', 'detail', todo.id], todo) }) return todos }, })}This would create a detail entry for each item in the list immediately. Since there is no one interested in those queries at the moment, those would be seen as inactive, which means they might be garbage collected after gcTime has elapsed (default: 15 minutes).
So if you use the push approach, the detail entries you’ve created here might no longer be available once the user actually navigates to the detail view. Also, if your list is long, you might be creating way too many entries that will never be needed.
🟢 staleTime is automatically respected
🟡 there is no good callback
🟡 might create unnecessary cache entries
🔴 pushed data might be garbage collected too early
Keep in mind that both approaches only work well if the structure of your detail query is exactly the same (or at least assignable to) the structure of the list query. If the detail view has a mandatory field that doesn’t exist in the list, seeding via initialData is not a good idea. This is where placeholderData comes in, and I’ve written a comparison about the two in #9: Placeholder and Initial Data in React Query.
That’s it for today. Feel free to reach out to me on bluesky (opens in a new window) if you have any questions, or just leave a comment below. ⬇️





